次梯度算法
本文内容包括:次梯度,次微分,次梯度算法
次梯度(Subgradients)
凸函数的次梯度:存在任意值使得: 凸函数在不可微时,次梯度可以看做是梯度的一种泛化。除了一些病态条件,凸函数的次梯度总是存在的。对于非凸函数而言,即使上述定义满足,次梯度也可能不存在。
次微分(Subdifferentials)
次微分是凸函数f在x点处的次梯度的集合: 次微分具有如下的性质:
- 是封闭的凸集;
- 是非空的(如果是非凸函数,则可以为空);
- 如果f在x处是可微的,则;
- 如果,那么f在x是可微的,。
次梯度性质
对于一个凸集,它的指示函数(Indicator function):
定理:对于,其中是C在x点的normal cone:
证明:
- 对于,由于normal cone的性质,,则,又因为,因此
- 对于,,(因为是有限的),不满normal cone的定义。
凸函数的次微分具有以下的计算特性:
- Scaling: 在时, 。如果,假设f 是凸函数,那么af 是凹函数,这个等式就不再成立。
- Addition:
- Affine composition: 如果,那么。
- Finite pointwise maximum: 如果,则 即是所有有效函数(达到最大值的函数)的次微分集合的凸包,意味着函数f(x)在点x的次微分等于能够取得最大值的函数在该点处的微分。
- General pointwise maximum: 如果,则
- Norms:使。考虑有,其中被定义为:,那么。
为什么要用次梯度
当目标函数光滑可微的时候,我们选择使用梯度下降算法,但事实上,并不是所有的目标函数都是光滑,或者处处可微的。如果能够计算次梯度,那么几乎能最小化任何凸函数(可能会很慢,但是是可能的)。
次梯度的优化条件(subgradient optimality condition):对于任意的函数f(不管是否是凸函数),如果是最优解当且仅当0属于f在的次梯度的集合: 证明如下:
如果f是凸函数且是可微的,那么,次梯度优化条件和凸函数的一阶最优性相同。
次梯度算法(Subgradient Method)
与梯度下降算法相似,将梯度替换成次梯度就是次梯度算法. 其中,是在处的次梯度。这个算法不一定是下降的(不一定单调)。
步长选择
固定步长:对于所有步长,。
逐渐变小的步长:选择满足如下条件的步长:
收敛性分析
在前面提到,算法并不是一定是下降的,那么为什么它一定能收敛呢?
如果函数是Lipschitz连续的,,即对于所有x,y,。
定理:对于一个固定步长t,次梯度算法满足: 对于一个逐渐变小的步长,次梯度算法满足:
/ TODO:证明以后来填坑 /
收敛率
次梯度算法的收敛率为,与梯度下降算法的收敛率相比,慢了很多。
随机次梯度算法(stochastic subgradient method)
与梯度下降算法的设定相同,考虑凸函数:
随机次梯度算法迭代:
其中是在第k次迭代的选择的索引,通过随机或者循环的规则选择,且。当每一个是可微的,这个算法就变成了随机梯度下降算法。
同样随机次梯度算法是可以证明其收敛性和收敛率的。
例子:逻辑回归
给定,对于,逻辑回归的损失函数为:
这是一个光滑的凸函数:
其中
正则化
正则化的逻辑回归的损失函数为:
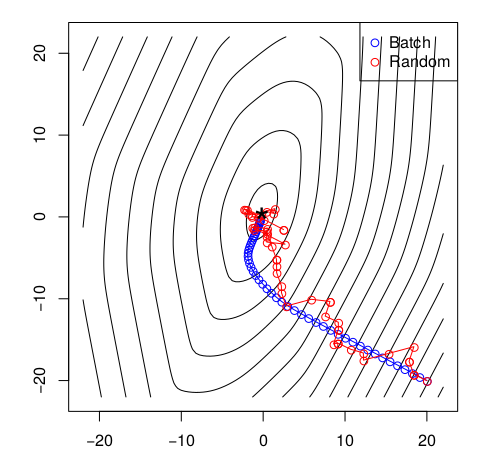
如果,我们称之为岭回归(ridge penalty);如果,我们称之为lasso回归(lasso penalty),对于岭回归,我们可以采用梯度下降算法求解;而对于Lasso问题就需要选择次梯度算法来求解了。下图数据样本n=1000, p=20,左图用岭回归,梯度下降算法,右图用lasso回归,用次梯度算法:
随机梯度下降
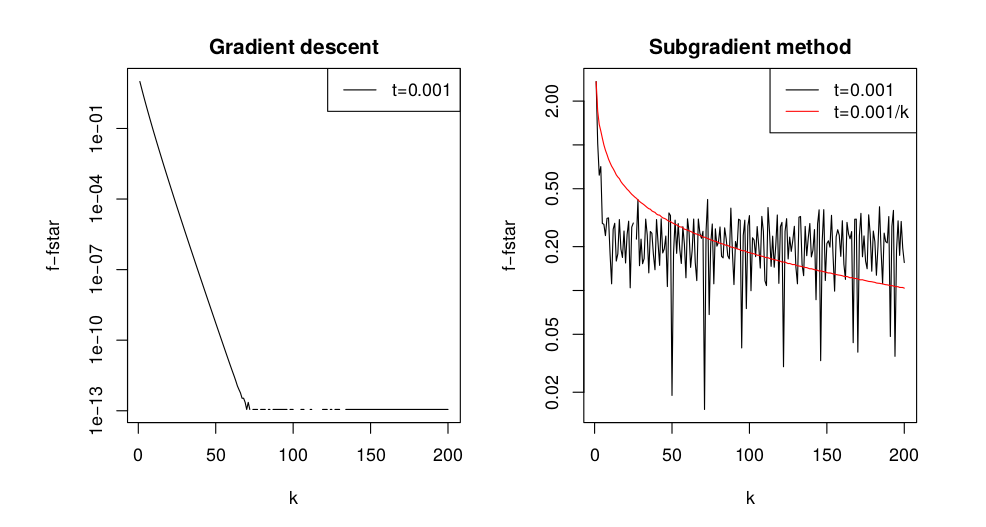
利用SGD算法来求解逻辑回归问题,随机梯度下降与batch梯度下降:
batch梯度下降时间复杂度:
stochastic梯度下降时间复杂度:
所以利用随机下降的方法在处理很大批量的数据的时候速度更快,而且前期的表现要好一点,但是后期在最优值处会更加震荡。一张经典的图片可以说明这一点: